万圣节问题(Halloween Problem)是数据库系统中的一个现象,它指的是当一个查询检索了一组行,然后修改了其中一行或多行,修改后的行再次满足查询的条件,进而导致在相同的更新操作中再次访问该行。在某些情况下甚至可能导致无限循环。
这个问题最初是由 Don Chamberlin、Pat Selinger 和 Morton Astrahan 在 1976 年的万圣节那天发现,当时他们正在处理的一个查询本应给那些收入低于 25,000 美元的员工加薪 10%,但执行完成后,数据库中所有员工的收入都至少达到了 25,000 美元。这是由于更新过的记录也对查询执行引擎可见,并且继续符合查询条件,记录多次匹配,每次匹配都被加薪 10%,直到它们都超过 25,000 美元。
Halloween Problem 这个名字并没有描述问题的性质,仅仅是因为它被发现的那天恰好是万圣节🎃。
Pat and Morton discovered this problem on Halloween… I remember they came into my office and said, “Chamberlin, look at this. We have to make sure that when the optimizer is making a plan for processing an update, it doesn’t use an index that is based on the field that is being updated. How are we going to do that?” It happened to be on a Friday, and we said, “Listen, we are not going to be able to solve this problem this afternoon. Let’s just give it a name. We’ll call it the Halloween Problem and we’ll work on it next week.” And it turns out it has been called that ever since.
自 1976 年万圣节问题被发现以来,至今已接近 50 年。尽管现代数据库技术已经取得了巨大进步,但是否所有数据库都完全避免了这样的问题呢?并非如此,CockroachDB 在 2020 年的 Pull Request 42862 里解决了被真正观测到的 Halloween Problem:
Moreover, this invalid behavior causes a real observable bug: a statement that reads and writes to the same table may never complete, as the read part may become able to consume the rows that it itself writes. Or worse, it could cause logical operations to be performed multiple times: https://en.wikipedia.org/wiki/Halloween_Problem
那 PostgreSQL 是否有这样的问题呢?如果你去搜 “postgres halloween problem”,会发现在 PG 的邮件列表有人问过这样的问题:
The Halloween problem is that it is a challenge for the database if you’re updating a field that is also in the WHERE clause of the same query.
I just saw a presentation from someone about how in SQL Server he recommended writing changes to a temp table and then writing them to the table as being much more efficient.
Does Postgres handle this problem efficiently, or should we follow a similar strategy?
Tom Lane 在第一时间做出了回复:
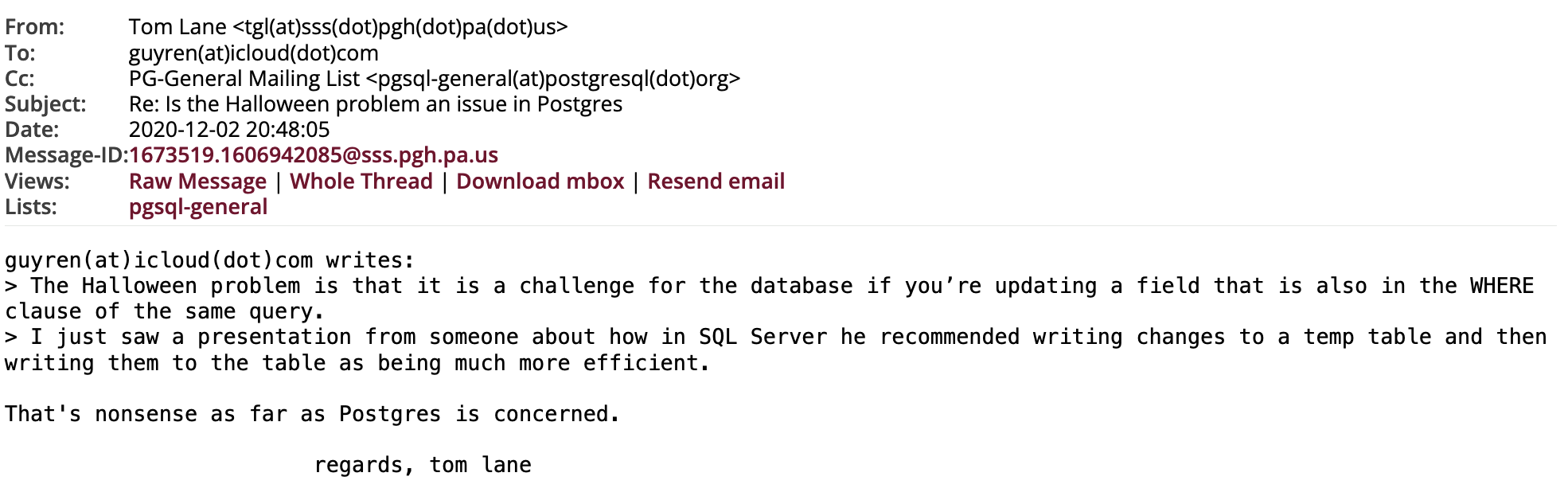
直译过来就是: 对于 Postgres 来说,这是无稽之谈。
邮件列表中没有进一步说明 Postgres 是如何避免这个问题的。本文后面的内容就来用实验解释为什么 PostgreSQL 不会有 Halloween problem。
PG 在更新数据时(ExecModifyTable)执行器是逐行进行的,并且更新的数据是写到空闲的空间,大概的过程是:
- 根据快照对一个 page 上的元组进行可见性判断并收集可见的元组(page_collect_tuples)
- 执行器挨个获取每条元组,并对满足条件的元组进行更新(ExecUpdate)
- 扫描下一个页重复执行上面的执行
如果第一个页上更新的数据写在第二个页上,在收集第二页上的元组时,如何保证之前更新的数据对执行器是不可见的呢?
Postgres 的元组头信息包含的 t_xmin, t_xmax 用于跟快照中的 xmin, xmax, xip[] 进行比较来判断该行数据是否对快照可见,对于更新产生的新数据,其 xmin 是当前的事务 id,一个事务中可能会有多个 statement,前面语句所做的变更要对后面的语句可见,当前语句所做的变更对当前语句自身又不可见,仅靠 xmin 不能处理这种情况,PG 中的 CommandId 用于解决上面的问题,在 tuple header 和快照中都有这个字段:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef struct SnapshotData
{
SnapshotType snapshot_type; /* type of snapshot */
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
/* skip skip */
/*
* For normal MVCC snapshot this contains the all xact IDs that are in
* progress, unless the snapshot was taken during recovery in which case
* it's empty. For historic MVCC snapshots, the meaning is inverted, i.e.
* it contains *committed* transactions between xmin and xmax.
*
* note: all ids in xip[] satisfy xmin <= xip[i] < xmax
*/
TransactionId *xip;
uint32 xcnt; /* # of xact ids in xip[] */
CommandId curcid; /* in my xact, CID < curcid are visible */
/* skip skip */
} SnapshotData;
snapshot.h 文件中有这样一段注释:
/*-------------------------------------------------------------------------
* A tuple is visible iff the tuple is valid for the given MVCC snapshot.
*
* Here, we consider the effects of:
* - all transactions committed as of the time of the given snapshot
* - previous commands of this transaction
*
* Does _not_ include:
* - transactions shown as in-progress by the snapshot
* - transactions started after the snapshot was taken
* - changes made by the current command
* -------------------------------------------------------------------------
*/
第五点是 Postgres 不会出现万圣节问题的原因之一;另一个原因是,在生成的执行计划的 HeapScanDesc 结构中的 rs_nblocks 字段记录了需要扫描的页面数,如果更新操作产生的数据被插入到新扩展的堆(heap)页中,那么这些新生成的页不会被纳入扫描范围。
接下来,我们通过一个实验来验证这一点。为了清晰地观察到 CommandId 的作用,我们将创建两个页面:第一个页面填满数据,而第二个页面仅包含一个元组。这样做的目的是确保在更新过程中,第二个页面上既包含更新前的数据,也包含由更新操作产生的新数据。
- 创建一个表
DROP TABLE IF EXISTS a;
CREATE TABLE a(id serial not null primary key, a integer not null, b text not null);
- 向表中插入数据(为了避免 text 字段被压缩或写入 toast 表,这里构造 1900 字符的随机字符串):
WITH random_chars AS (
SELECT chr(trunc(65 + random() * 58)::int) AS char
FROM generate_series(1, 1900)
),
random_string AS (
SELECT string_agg(char, '') AS random_string
FROM random_chars
)
INSERT INTO a (a, b)
SELECT i, random_string
FROM random_string, generate_series(1, 5) i;
- 确认数据没有被压缩或写入 toast 表
-- create extension if not exists pageinspect;
SELECT * FROM heap_page_items(get_raw_page('a', 0));
SELECT * FROM page_header(get_raw_page('a', 0));
select * from pg_toast.pg_toast_xxxxx;
- 在以下几个位置打断点
- page_collect_tuples https://github.com/postgres/postgres/blob/REL_17_STABLE/src/backend/access/heap/heapam.c#L469
- HeapTupleSatisfiesMVCC https://github.com/postgres/postgres/blob/REL_17_STABLE/src/backend/access/heap/heapam_visibility.c#L963
- ExecScan https://github.com/postgres/postgres/blob/REL_17_STABLE/src/backend/executor/execScan.c#L197
- ExecModifyTable https://github.com/postgres/postgres/blob/REL_17_STABLE/src/backend/executor/nodeModifyTable.c#L4104
- 执行更新语句
UPDATE a SET a = a + 1 WHERE a < 3;
- 在执行过程中观察断点所在函数的执行状况并用 pageinspect 观测页面变化
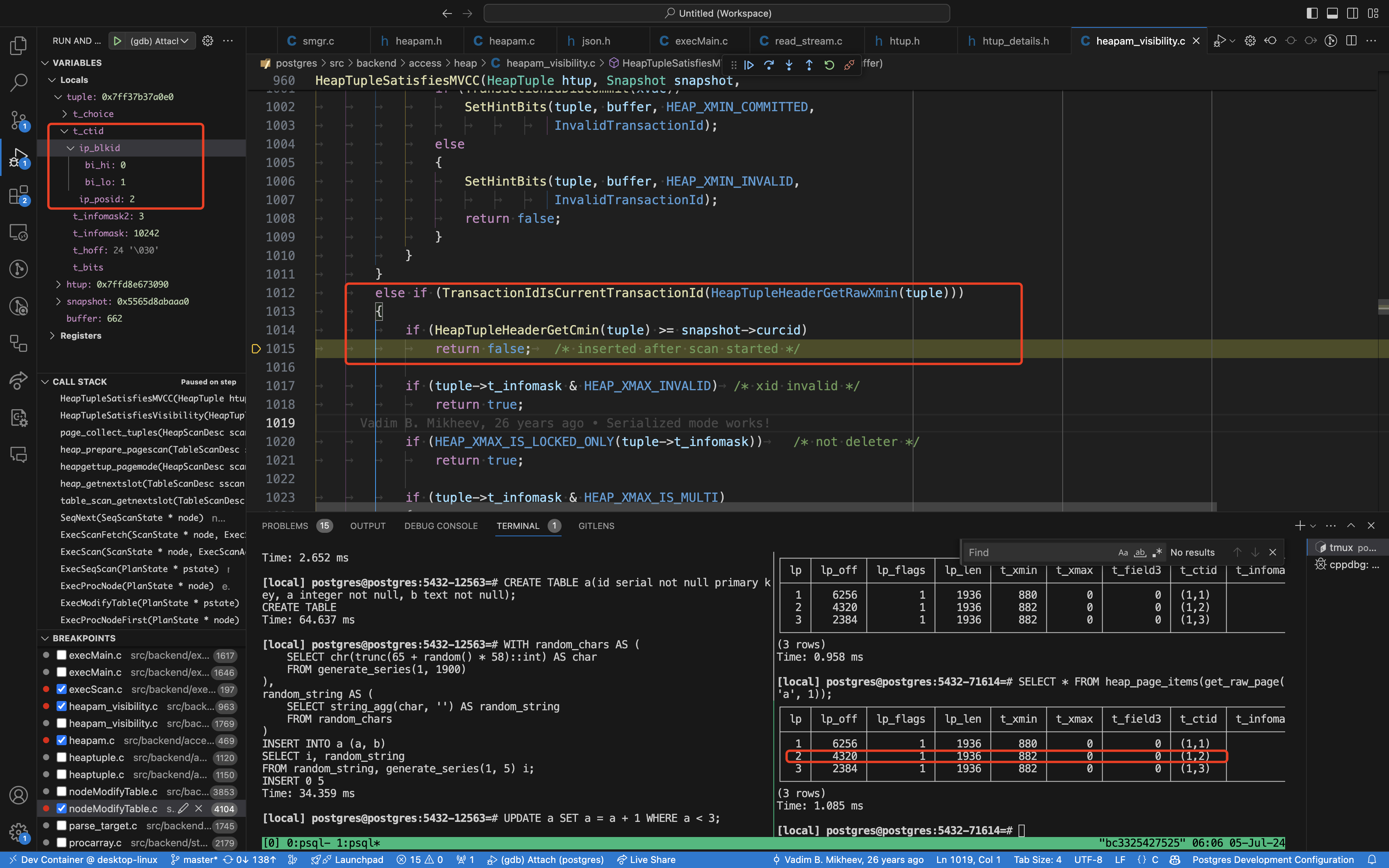
- page_collect_tuples 扫描 page 0 收集了四个满足条件的元组
- 由于有 a < 3 的条件,ExecScan 中检查后只有两个元组满足条件
- ExecModifyTable 中的 ExecUpdate 只执行两次,每次断点执行后用 pageinspect 观察 page 1 页面的变化
- page_collect_tuples 扫描 page 1,ctid 为 (1,1) 的元组满足条件
- ctid 为 (1, 2), (1, 3) 的元组为该更新语句自己生成的元组,其 tuple header 中记录的 CID == snapshot->curcid,所以它们是不可见的
下面是一个用 gdb 观测这个实验的截图:
另外我会对本文的内容录制一期视频,感兴趣的可以关注以下链接:
https://github.com/PgTalk/PgTalk/issues/11